이번 시간에는 회귀분석을 통해 머신러닝에 대해 이해해 보도록 하겠습니다.
회귀분석에 사용할 데이터는, sklearn 패키지의 보스턴 주택 가격 데이터입니다.
보스턴 주택 가격을 종속 변수, 나머지 변수들을 독립변수로 하여 모델을 만들고 검증하는 과정을 통해, 머신러닝을 이해할 수 있습니다.
데이터 불러오기 및 이상 여부 체크
먼저 데이터를 불러온 뒤, 이상 여부를 체크합니다.
df.info()를 통해 확인해 보면, CHAS와 RAD가 category형 변수임을 알 수 있습니다.
회귀 분석을 위해, RAD는 int형 변수로 변경해 줍니다.
CHAS는 0 혹은 1 값만을 가져 분석에 거의 영향이 없으므로, 향후 분석에서 제외해 줍니다.
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
# Load data
df, price = datasets.fetch_openml('boston', return_X_y=True)
df['PRICE'] = price
# Check for data abnormalities
print(df.info())
df['RAD'] = df['RAD'].astype(int)
print(df.isna().sum())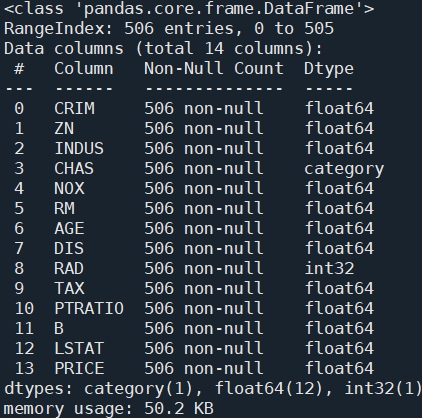
df.isna().sum() 함수를 사용해서, 데이터에 결측치가 없음도 확인합니다.

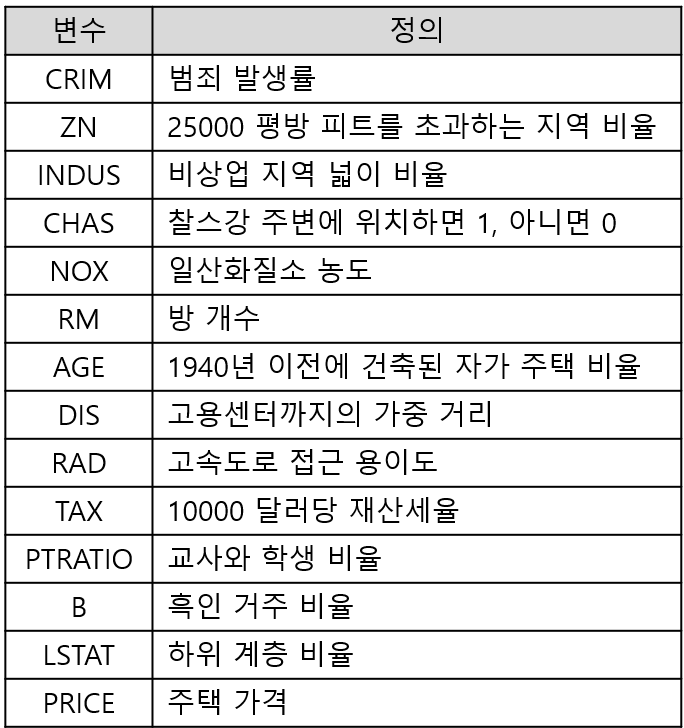
참고로, 변수들의 의미는 다음과 같습니다.
데이터 전처리
회귀분석을 위해 'PRICE'를 종속변수, 나머지 변수들을 독립변수로 지정해 줍니다.
그 후 train_test_split 함수를 이용하여, 학습과 평가를 위한 데이터를 8:2 비율로 나눠 줍니다.
각 독립변수들이 종속변수에 미치는 영향을 동일하게 하기 위해, MinMaxScaler 함수를 사용하여 독립변수들을 정규화해 줍니다.
# Data preprocessing
x = df[['CRIM','ZN','INDUS','NOX','RM','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT']].values
y = df['PRICE'].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# Normalization
scaler = MinMaxScaler()
x_train_scaled = scaler.fit_transform(x_train)
모델 학습
LinearRegression() 함수를 사용하여 모델을 만들어 줍니다.
그 후, 모델을 통해 예측된 주택 가격과 실제 주택 가격을 비교하여 모델의 성능을 알아볼 수 있습니다.
MAE(Mean Absolute Error) 값은 3.13 수준, R^2 값은 0.77 수준이므로, 만들어진 모델이 양호함을 알 수 있습니다.
# Model training
linear = LinearRegression()
linear.fit(x_train_scaled, y_train)
pred_train = linear.predict(x_train_scaled)
mae = mean_absolute_error(y_train, pred_train)
mse = mean_squared_error(y_train, pred_train)
rmse = np.sqrt(mse)
r2 = r2_score(y_train, pred_train)
print('MAE: {0: .5f}'.format(mae))
print('MSE: {0: .5f}'.format(mse))
print('RMSE: {0: .5f}'.format(rmse))
print('R2: {0: .5f}'.format(r2))
모델 성능 평가
앞에서 만들어진 모델에 테스트 데이터를(x_test_scaled) 입력하여, 주택 가격을 예측해 봅니다.
실제 주택 가격과(y_test) 비교 시, MAE는 3.84 수준, R^2는 0.58 수준의 성능을 보입니다.
# Model performance evaluation
x_test_scaled = scaler.transform(x_test)
pred = linear.predict(x_test_scaled)
mae = mean_absolute_error(y_test, pred)
mse = mean_squared_error(y_test, pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, pred)
print('MAE: {0: .5f}'.format(mae))
print('MSE: {0: .5f}'.format(mse))
print('RMSE: {0: .5f}'.format(rmse))
print('R2: {0: .5f}'.format(r2))
모델의 성능을 그래프를 통해 가시화할 수도 있습니다.
# Plot real and predicted prices
plt.figure()
plt.plot(y_test, color='red', label='Real price')
plt.plot(pred, color='blue', label='Predicted price')
plt.title('Predict Boston house price')
plt.xlabel('Data index')
plt.ylabel('House price')
plt.legend()
plt.show()
이와 같이 회귀분석을 진행하면서, 머신러닝의 각 과정에 대해(데이터 전처리, 모델 학습, 모델 성능 평가) 쉽게 이해할 수 있습니다.
'파이썬' 카테고리의 다른 글
| 다항 회귀(Polynomial Regression) 분석 (0) | 2025.05.05 |
|---|---|
| 분류분석을 통한 머신러닝 이해 (0) | 2025.05.01 |
| 주성분 분석 (PCA: Principal Component Analysis) (0) | 2025.04.13 |
| ProfileReport : 데이터 분석을 빠르게 (2) | 2025.04.12 |
| 두 집단의 평균 차이를 통계적으로 판단 (0) | 2025.04.06 |



